Spring 2001
Professor John Chuang
School of Information Management and Systems
Group A Team Members
Link-inator is a client application for web site administrators. It takes a URL from the command line and checks all outbound links from that page. It then summarizes which URLs were valid and flags those which returned error messages and reports the nature of the error.
Both the main program and the text parser are written in Java.
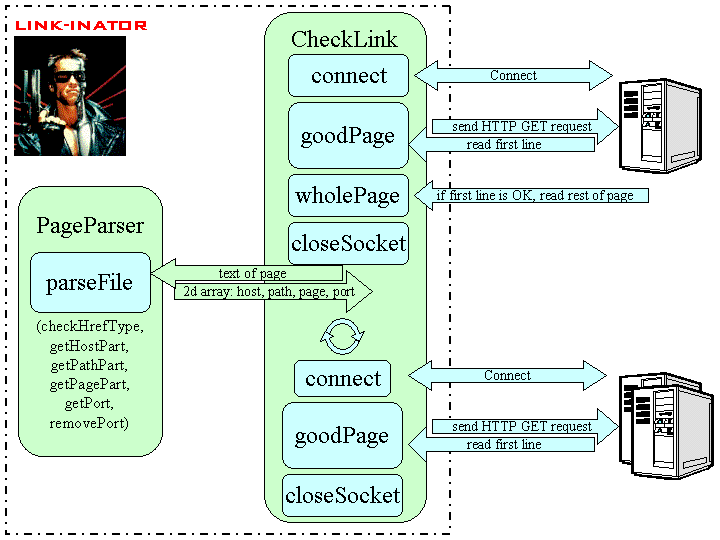
The software consists of two modules, CheckLink and PageParser, each written in Java.
The CheckLink module:
- determines whether a connection can be established with the page's host
- determines whether the specific link is valid
- fetches the page specified
- passes page to parsing module
- checks the status of subsequent links when they are returned from the PageParser
- Returns a report to the user cataloging valid and invalid links and the error messages returned, flags bad links for manual checking
It uses the following methods:
connect: Creates a socket connection to a specified host and port number (default = 80), establishes input and output streams, and returns a Socket object.
goodPage: Sends an HTTP GET message to the socket, then reads the first line of data from the socket and checks the HTTP status code. Returns a boolean value that is true for good status (status code = 200) or false otherwise.
wholePage: Reads the remainder of the HTML page and returns a String containing the entire text.
closeSocket: Closes the previously connected socket and its input and output streams.
The PageParser module:
- parses HTML for href statements
- creates a data structure consisting of a two-dimensional string array with hostname, path, pagename, port number, and the entire URL
- returns this data structure to the CheckLink module
It uses the following methods:
checkHrefType: eliminates extraneous hrefs such as mailto links
getHostPart: extracts the hostname from the href
getPathPart: extracts the path to the page from the href
getPagePart: extracts the filename from the href
getPort: extracts the port number (if any) from the hostname.
removePort: removes the port number from the hostname
While the initial specification of this software seemed relatively straightforward, many interesting issues arose regarding parsing an html file for outbound links. Most of these issues had to do with the variety of ways in which links can be specified. As a result, the text parser was the more difficult of the two modules to write because we had to deal with more URL variations than we expected.
There were also issues in dealing with the HTTP specification for the GET message. The specification actually states that each line of the message ends with CRLF (carriage return line feed). We initially assumed that this was equivalent to a new line character in Java (/n). This syntax worked for many, but not all, servers, presumably because some servers are more forgiving than others regarding their insistence on adherence to standards. In debugging the code for servers which refused the GET message as written, we discovered that the correct Java code for CRLF is a return character plus a new line character(\r \n). Using this syntax more perfectly follows the HTTP specification and seems to satisfy all servers.
We initially expected to write the parsing module in Python. Upon researching the issue further, however, we discovered that integrating the two modules might not be as trivial as we expected. In addition, parsing functions turned out to be easier to implement in Java than we expected. Since the team's expertise was more heavily weighted to Java than Python, we decided to implement the entire project in Java.
Future extensions to the program might include:
- Extending the program to email the contents of the error file to the site administrator. This would invoke a Java class to email a summary of the bad links with a reference to a file with a complete report to the site administrator. This would add one more optional argument to the command line.
- Extending the program to check the links on multiple pages, either specified on the command line or referenced in a file. This would be very similar to the functionality that is already present in the program, since the current code loops through the set of links found on the first page. The code could be extended to accept a filename (containing the set of pages to check) at the command line, possibly pass that file to a new method in the PageParser module (to extract the host and page information), and perform an outer loop through each of the specified pages.
- Support for frames pages. Support for frames pages would use logic similar to that for supporting recursive link checking across a site. Frames would be treated as linked-to pages and those pages would be recursively checked. See below.
- Recursive crawling of an entire site. This would involve a substantial rewrite of the code but could be tremendously useful to a sight administrator. It would involve parsing the original page for outbound links and storing the link information in a delimited file with the addition of information about the page the link was located on. Duplicate links could be removed. Then the parser could recursively step through each linked-to page, all the while comparing links and linked-from information with the main delimited link file to be sure that it had not already checked a link from the same page. This would stop the program from performing an infinite loop.
Source code:
CheckLink: [.java] [.txt] checks links for errors, outputs information on bad links with their associated error messages
PageParser: [.java] [.txt] parses an HTML page and returns a data structure containing URLs and ports for submission to CheckLink
Note: The .java files may be formatted badly if downloaded from Internet Explorer. If this occurs, download the .txt files instead and rename to .java before compiling.
Executables:
CheckLink.class
PageParser.class
Simple Usage Instructions
To use Checklink:
To compile the code:
1. Download
CheckLink.java and PageParser.java to your directory.
2. Compile the two files like so:
- javac PageParser.java
- javac
CheckLink.java
3. You now
have the compiled code in your directory.
4. From the command line in dos or unix, type:
% Java CheckLink hostname [pagename] [port number]
5.That's it! CheckLink will let you know what it's doing and display information about the links on the page you specified.
All team participants wrote the specification for the program together, creating the pseudo code in the early design meetings. Jean Anne wanted to practice her Java skills and so wrote the actual code for Link-inator. Jennifer and Ian assisted in bug fixes and composed all written materials for the project.
Jean Anne learned that debugging a socket connection can be extremely frustrating because the connection can fail in a way that is not informative. Specifically, when the CRLF format was not correct, some servers would simply hang without returning any kind of error message.
Ian and Jennifer learned more about object-oriented programming in general and Java specifically. We also learned more about debugging techniques.
The group also did research on HTTP message formats and status codes. We learned that the format for HTTP messages is specified in the RFC 2616: Hypertext Transfer Protocol -- HTTP/1.1. This RFC also defines all of the status codes which we used for determining which links are good and for providing feedback to the web site administrator about the nature of "bad" (i.e. other than status code 200) links.
Perhaps most applicable to all programming projects, we learned not to underestimate the complexity of parsing text materials that are not in a fixed format (i.e. anything created by people).